wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading · GitHub
Por um escritor misterioso
Descrição
This repository contains the three WikiReading datasets as used and described in WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia, Hewlett, et al, ACL 2016 (the English WikiReading dataset) and Byte-level Machine Reading across Morphologically Varied Languages, Kenter et al, AAAI-18 (the Turkish and Russian datasets). - wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading
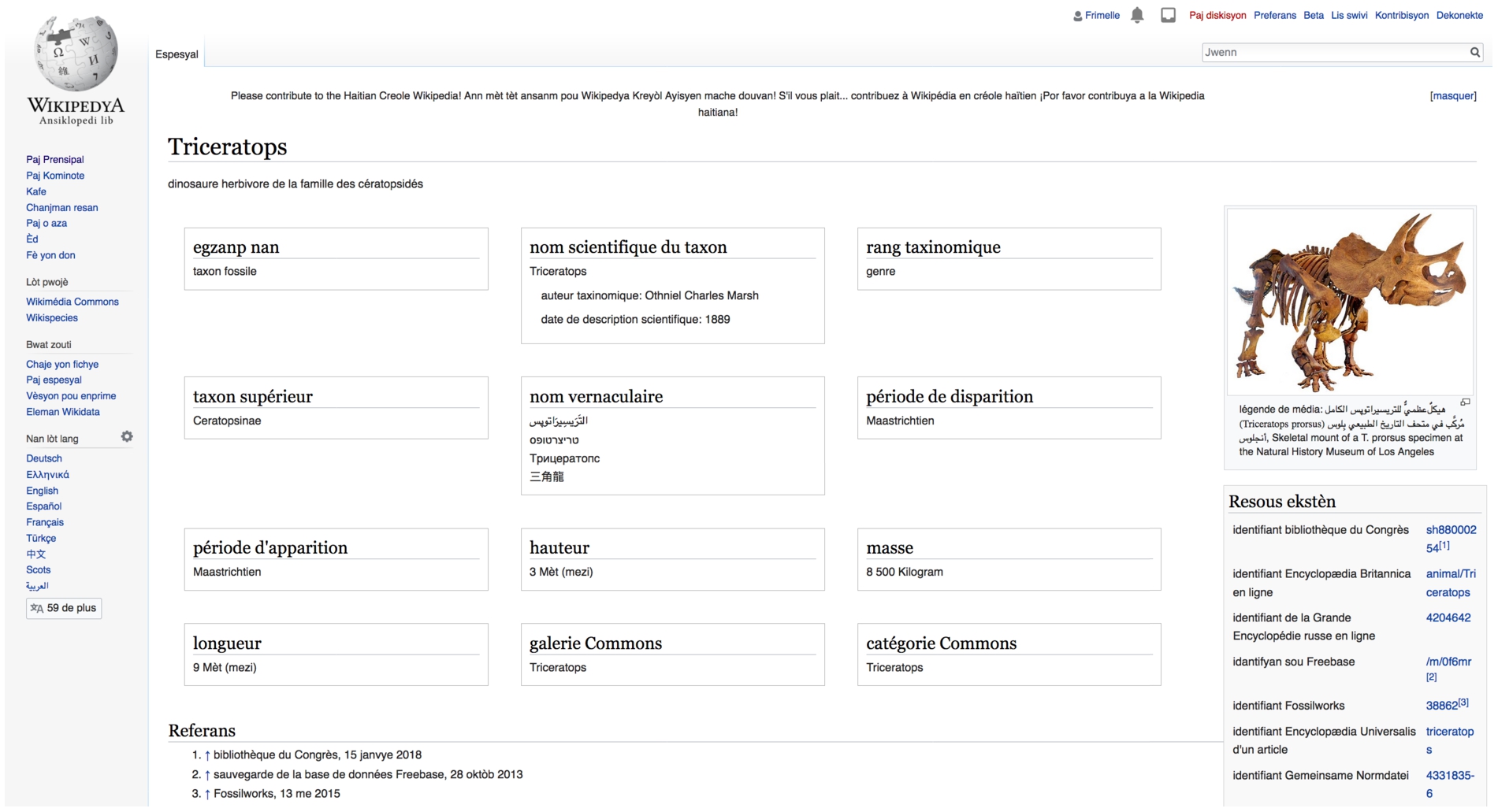
Using natural language generation to bootstrap missing Wikipedia articles: A human-centric perspective - IOS Press
Steve Blank Artificial Intelligence and Machine Learning– Explained
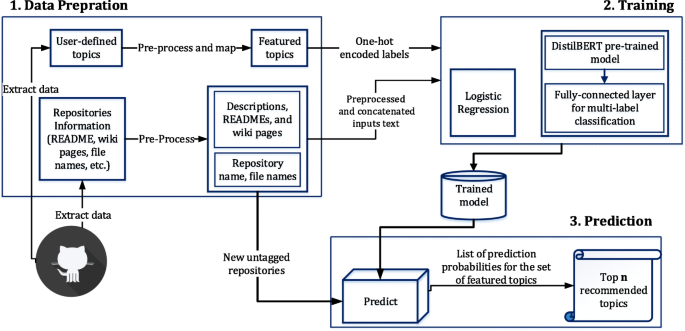
Topic recommendation for software repositories using multi-label classification algorithms
GitHub - google-research-datasets/WikipediaAbbreviationData: This data set consists of 24,000 English sentences, extracted from Wikipedia in 2017, annotated to support development of an abbreviation expansion system for text-to-speech synthesis (e.g.

Wikipedia on the CompTox Chemicals Dashboard: Connecting Resources to Enrich Public Chemical Data
How many articles (Wiki+Book corpus) do Bert use in pretraining? · Issue #570 · google-research/bert · GitHub
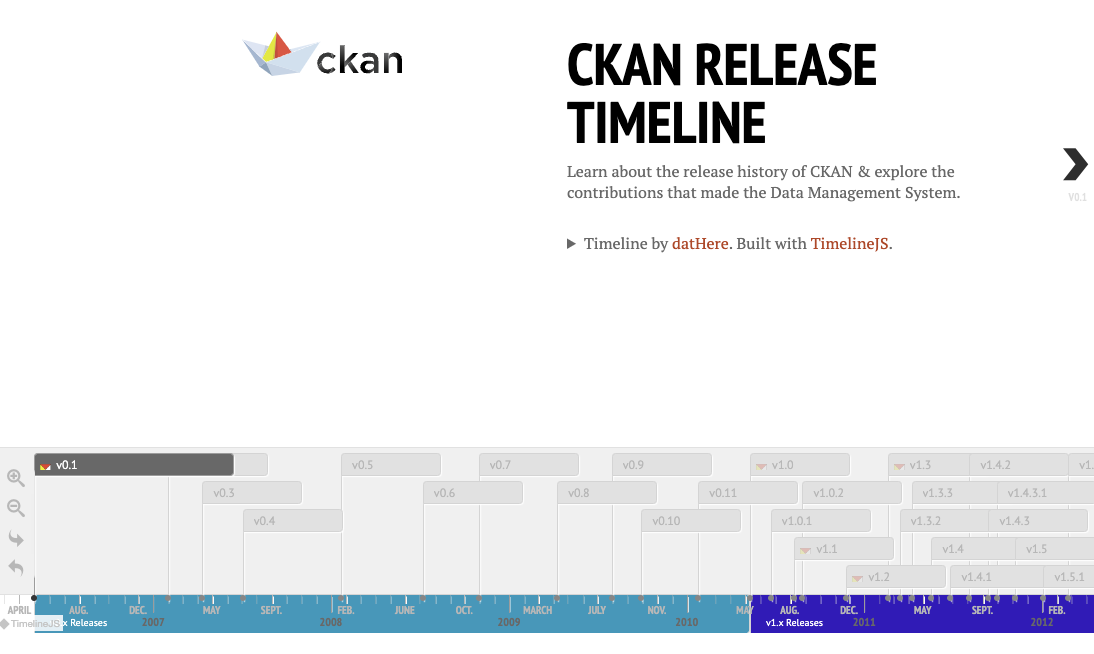
CKAN Major Releases Timeline: A Journey of Continuous Improvement
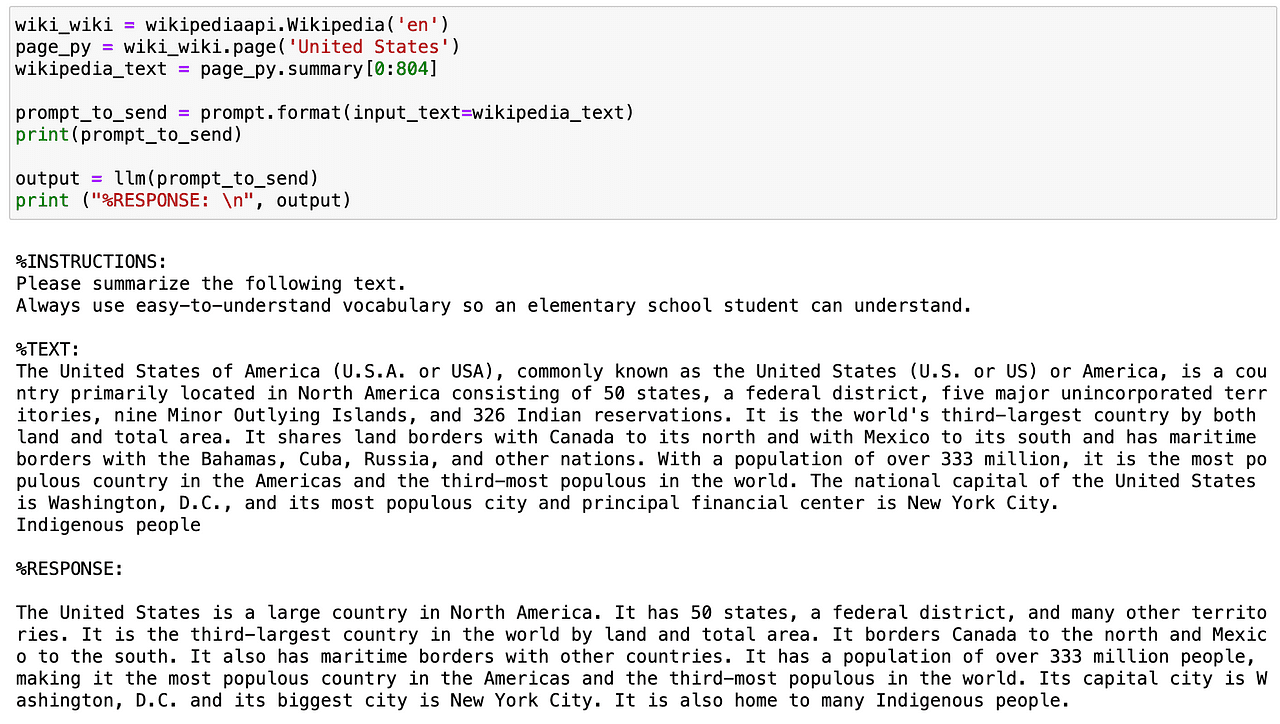
Transforming AI with LangChain: A Text Data Game Changer - KDnuggets

Datamining Wikipedia and writing JS with ChatGTP just to swap the colours on university logos…
de
por adulto (o preço varia de acordo com o tamanho do grupo)






